文字列は、16ビット値が順序付けて並べられた不変のデータです。この16ビット値は、それぞれ Unicode 文字を表します。文字列は、JavaScript において、テキストを表現するために用意された型です。文字列の長さは、文字列に含まれる 16ビット値の数になります。JavaScript の文字列は、配列と同様に、最初の文字を 0 としてインデックスします。つまり、最初の 16ビット値が位置 0、2番目の 16ビット値が位置 1、以降同様です。空文字列は、長さが 0 の文字列となります。JavaScript には、1文字の文字列を表すような特別な型は用意されていません。16ビット値を 1つだけ表すには、長さ 1 の文字列を使います。
JavaScriptプログラム中に文字列を記述するときは、シングルクォート( ' )、ダブルクォート( " )、またはバッククォート( ` )で文字列を囲みます。ダブルクォート( " )で囲まれた文字列の中にシングルクォート( ' )で囲まれた別の文字列を挿入したり、シングルクォートで囲まれた文字列の中にダブルクォートで囲まれた別の文字列をリテラルの一部として挿入したりすることもできます。
'これは文字列です。';
"これも文字列です。";
`これも文字列です。`;
JavaScriptの場合には、シングルクォート( ' )またはダブルクォート( " )のどちらを使っても特に違いはありません。一方、前後でクォートの種類が異なると、エラーになります。
❌ クォートの種類が異なるとエラー
'これはエラーになります。";
シングルクォートやダブルクォートを文字列に含めたい場合もあるでしょう。そのようなときには、文字列に含めたいクォートの種類と別のクォートで全体を囲みます。
console.log('今日のおかずは"さば"です!'); // 今日のおかずは"さば"です!
console.log("今日のおかずは'さば'です!"); // 今日のおかずは'さば'です!
❌ 悪い例
console.log("今日のおかずは"さば"です!");
console.log('今日のおかずは'さば'です!');
悪い例では、ダブルクォートの中でさらにダブルクォートを使っています。文字列は、ダブルクォート同志またはシングルクォート同士で囲まれた範囲なので、悪い例の場合には JavaScriptエンジンは次のようにコードを分解して解釈します。
"今日のおかずは" さば "です!"
これだと「さば」の部分が不明なキーワードとなるため、プログラムでエラーが発生します。
もしダブルクォートの中でダブルクォートを文字として表示したい場合には、バックスラッシュ( \ )を使います。
console.log("今日のおかずは\"さば\"です!"); // 今日のおかずは"さば"です!
このようにバックスラッシュに続けてダブルクォート( \" )を使うことで、ダブルクォートを文字として表示できます(シングルクォートの場合も同様です)。このようなバックスラッシュに続く特殊な文字列をエスケープシーケンスと呼びます。
JavaScriptの文字列では、バックスラッシュ( \ )を特別な意味で使用します。バックスラッシュの直後に特定の文字を記述することで、特定の制御コードを表せます。つまり、その文字はそのまま表示されるわけではありません。例えば、\n は改行文字を表すエスケープシーケンスです。
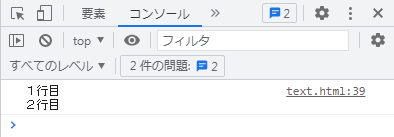
console.log('1行目\n2行目');
例えば、\' について考えてみましょう。このコードは、シングルクォートそのものを表すエスケープシーケンスです。これは、シングルクォートに囲まれた文字列リテラルの中にアポストロフィを含めたいときに使用します。なお、エスケープは通常の解釈をしないという意味です。ですから、文字列の終端を表すというシングルクォートの解釈を変更して、そのままの記号、つまりアポストロフィそのものとして使用するという意味になるのです。
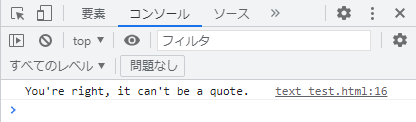
console.log('You\'re right, it can\'t be a quote.');
このように、プログラムの動作として表現したい文字列を、エスケープシーケンスを使って表現できます。
下表に、JavaScriptエスケープシーケンスとその意味をまとめておきます。この表を見るとわかるように、Latin-1文字コードや Unicode文字コードを 16進数で指定して、任意の文字を表す汎用的なエスケープシーケンスもあります。例えば、\xA9 は著作権者表示の記号です。このエスケープシーケンスは、Latin-1文字コードで A9 (16進数)の文字を表します。同じように、\u を使えば、4桁の 16進数で任意の Unicode文字を指定できます。例えば、\u03c0 は π を表します。
\b\t\v\n\f\r\"\'\`\\\0\xXX\uXXXX\u{XXXXXX} 上表で示した文字以外の文字の前にバックスラッシュを記述した場合、バックスラッシュは単純に無視されます(もちろん、将来のバージョンでエスケープシーケンスが増える可能性はあります)。例えば、\# と記述した場合は # と同じ意味になります。また、ECMAScript 5 では、改行の直前にバックスラッシュを記述することで、文字列を複数行にまたがって記述できます。
ECMAScript 3 では、行をまたいで文字列を記述することはできません。これに対して、ECMAScript 5 では、文字列を複数の行に分割することができます。分割する場合には、各行の末尾にバックスラッシュ( \ (日本語環境では円マークで代用))を記述します。バックスラッシュや、バックスラッシュの後の改行文字も、文字列リテラルには含まれません。文字列リテラルに改行文字を含めたい場合には、「 \n 」という文字並び(後述)を記述してください。
"two\nlines"
// 2行を表す文字列を 1行で記述。
"one\
long\
line"
// 1行文字列を 3行で記述。ECMAScript 5 のみ。
文字列を単一引用符で囲んでいる場合は、英語の短縮形や所有格に注意してください。例えば、「 can't 」や「 O'Reilly's 」といった文字列です。アポストロフィは単一引用符と同じ文字なので、単一引用符で囲んだ文字列中にアポストロフィが含まれる場合は、バックスラッシュ( \ )を使って「エスケープ」しなければなりません(次項を参照)。
クライアントサイド JavaScript プログラミングでは、JavaScript コードに HTML 文字列を埋め込んだり、HTML 文字列に JavaScript コードを埋め込んだりすることがよくあります。このため、JavaScript と HTML で文字列の囲み方を変えるように習慣づけるようにするとよいでしょう。例えば、JavaScript では単一引用符で文字列を囲むようにし、HTML では二重引用符で文字列を囲むようにします。次の例では、「 Thank you 」という文字列を単一引用符で囲んで JavaScript 式に挿入し、全体は HTML イベントハンドラ属性として二重引用符で囲んでいます。
<button onclick="alert('Thank you')">Click Me</button>
JavaScriptには文字列を連結する機能があります。数値に対してプラス( + )演算子を適用すると、加算が実行されます。文字列にプラス( + )演算子を適用すると、前の文字列に後の文字列が連結されます。
console.log("こんにちは。" + '太郎さん!''); // 「こんにちは。太郎さん!」になる。
ある文字列の長さは、その文字列に含まれる 16ビット値の数で表されます。文字列の長さは、その文字列の length プロパティで調べられます。変数 s に格納された文字列の長さを求める場合は、次のように記述します。
s.length
ここで紹介した length プロパティの他にも、文字列に対して呼び出すことのできるメソッドが数多く存在します。
var s = "hello, world"
// 例となるテキスト。
s.charAt(0)
// => "h": 最初の文字。
s.charAt(s.length-1)
// => "d": 最後の文字。
s.substring(1,4)
// => "ell": 2番目と 3番目と 4番目の文字。
s.slice(1,4)
// => "ell": 同じような処理。
s.slice(-3)
// => "rld": 最後から 3文字。
s.indexOf("l")
// => 2: 最初の l の位置。
s.lastIndexOf("l")
// => 10: 最後の l の位置。
s.indexOf("l", 3)
// => 3: 3文字目以降で最初の l の位置。
s.split(", ")
// => ["hello", "world"] サブ文字列に分割。
s.replace("h", "H")
// => "Hello, world": すべての文字を置き換える。
s.toUpperCase()
// => "HELLO, WORLD"
JavaScript では文字列は不変です。replace() や toUpperCase() などのメソッドでは、新しい文字列が返されます。メソッドを呼び出した文字列を変更するわけではありません。
ECMAScript 5 では、文字列を読み出しのみの配列のように扱うことができます。つまり、charAt()メソッドではなく、角括弧を使うことで、文字列中の個々の文字(16ビット値)にアクセスできます。以下の例を見てください。
s = "hello, world";
s[0]
// => "h"
s[s.length-1]
// => "d"
Firefox などの、Mozilla ベースの Webブラウザでは、以前からこの形式で文字列中の文字をアクセスできるようにしていました。この機能が ECMAScript 5 で標準化される前に、最近のブラウザは Mozilla の機能を追従して実装しています。ただし、IE だけは例外です。
JavaScript には、テキストパターンを表すオブジェクトを生成するために、RegExp() コンストラクタが定義されています。このパターンは、正規表現を使って記述します。JavaScript では、正規表現の構文として Perl の構文を使っています。文字列と RegExp オブジェクトの両方で、正規表現を使ったパターンマッチングや検索置換処理を行うためのメソッドが用意されています。
RegExp は、JavaScript の基本的な型ではありません。Date オブジェクトと同様に、便利な API が用意されたオブジェクトの一種です。正規表現の文法は複雑で、API も簡単ではありません。詳細は別途紹介します。テキスト処理において、RegExp は非常によく使われる強力なツールなので、この項で概要を紹介しておきます。
RegExp は基本的な型ではありませんが、JavaScript プログラム中に直接記述するためのリテラル形式の文法が用意されています。テキストをスラッシュで囲むことで、正規表現リテラルを記述できます。末尾のスラッシュの後ろには、さらに文字を記述できます。この文字で、パターンの意味を変更できます。いくつか例を紹介します。
/^HTML/
// 文字列の先頭の H T M L という文字列にマッチ。
/[1-9][0-9]*/
// 0以外の数字の後に続く任意の個数の数字にマッチ。
/\bjavascript\b/i
// 大文字小文字区別なしに「javascript」という単語にマッチ。
RegExp オブジェクトには、便利なメソッドがたくさん用意されています。また、文字列にも、RegExp を引数として利用するメソッドが用意されています。
var text = "testing: 1, 2, 3";
// 例となるテキスト。
var pattern = /\d+/g
// 1個以上の数字例に全てマッチ。
pattern.test(test)
// => true: マッチする部分が存在する。
text.search(pattern)
// => 9: 最初にマッチした文字の位置。
text.match(pattern)
// => ["1", "2", "3"]: すべてのマッチを含む配列。
text.replace(pattern, "#");
// => "testing: #, #, #"
text.split(/\D+/);
// => ["", "1","2","3"]: 数字以外の文字で配列に分割。