JavaScript uses the UTF-16 character code and can represent a wide variety of characters.
みなさんは「文字コード」が何かわかりますか?文字コードとは、コンピューター内部において文字を表すための規約です。
つまり、コンピューター内部では数値のみが扱われるため、文字にはそれぞれ数値が割り当てられるのです。文字コードは複数種類存在するので、文字から数値への変換方法はひとつではありません。違う文字コードを使用すれば、同じ文字でも違う数値に変換されるのです。
主な文字コードは
などが挙げられます。
ASCII コードは、英数字と一部の記号のための文字コードです。もっとも基本的な文字コードとして全世界に普及しているものです。
Unicode は、全世界の文字に適用する目的で作成された文字コードです。Unicode は様々な種類が存在し、UTF‐8 は日本語を使用する際の文字コードとして利用されています。
Shift-JIS は日本語の文字のための文字コードで、日本語を使用する際には最も一般的に普及している文字コードのひとつです。
みなさんも、上記のうちのひとつくらいは聞いた事があると思いまが、文字コードについての知識があるとプログラミングにおいてとても役に立つので、覚えておいて損はありません。
JavaScriptは文字コードとして Unicodeを採用し、エンコード方式として UTF-16を採用しています。 この UTF-16を採用しているのは、あくまで JavaScriptの内部で文字列を扱う際の文字コード(内部コード)です。 そのため、コードを書いたファイル自体の文字コード(外部コード)は、UTF-8のように UTF-16以外の文字コードであっても問題ありません。
これらの文字コードは意識していなかったように、内部的にどのような文字コードで扱っているかは意識せずに文字列処理ができます。 しかし、JavaScriptの Stringオブジェクトにはこの文字コード(Unicode)に特化した APIもあります。 また、絵文字を含む特定の文字を扱う際や「文字数」を数えるという場合には、内部コードである UTF-16を意識しないといけない場面があります。
JavaScript は、大文字と小文字を区別します。キーワード、変数、関数名、識別子で、大文字と小文字は厳密に区別されます。例えば、while キーワードであれば、必ず小文字で入力しなければなりません。「While」や「WHILE」は無効になります。言い換えると、online、Online、OnLine、ONLINE は、それぞれ異なる変数名として扱われます。
クライアントサイド JavaScript のオブジェクトやプロパティには、HTML のタグや属性と同じ名前が使われているものがたくさんあります。HTML では、これらのタグや属性で大文字と小文字が区別されません。しかし、JavaScript では一般的に、これらはすべて小文字で記述します。例えば、HTML では、イベントハンドラ onclick を onClick や OnClick などと記述することが多いのですが、JavaScript コードで記述する場合は、全て小文字で onclick と記述しなければなりません(なお XHTML では大文字と小文字を区別するので、XHTML の場合も全て小文字で記述します。)。
JavaScript は、プログラム内のトークンを区切る空白を無視します。また、一般的には改行も無視します(ただし、例外があります)。つまり、プログラム内に空白や改行を自由に挿入できるので、整形やインデントを施してコードを読みやすくすることができます。
※当サイトでは、日本語環境では半角バックスラッシュ「 \(これは全角)」を表示することが難しい場合、キーボードのバックスラッシュを押した時に表示される、円マーク「 ¥ 」で代用表示しています。詳しくは、「 Wikipedia 」でご確認ください。
通常のスペース文字( \u0020 )の他に、タブ( \u0009 )、垂直タブ( \u000B )、改頁( \u000C )、ノーブレークスペース( \u00A0 )、バイトオーダーマーク( \uFEFF )や、Unicode カテゴリ「 Zs 」に含まれるすべての文字も、JavaScript では空白として取り扱われます。また、JavaScript は、改行( \u000A )、復帰( \u000D )、ラインセパレータ( \u2028 )、パラグラフセパレータ( \u2029 )を行末記号と見なします。復帰、改行が連続する場合も、1つの行末記号として扱います。
RIGHT-TO-LEFT MARK( \u200F )や LEFT-TO-RIGHT( \u200E )などの、Unicode 制御文字(カテゴリ Cf )は、テキストの表示方法を制御します。これらの文字は、英語以外の言語では、文字列を正しく表示するために重要な文字です。そこで、JavaScript では、コメントや文字列リテラル、正規表現リテラルにこれらの文字を使うことが許されています。ただし、JavaScript プログラムの識別子(変数名など)には使えません。特例として、ZERO WIDTH JOINER( \u200D )と ZERO WIDTH NON-JOINER( \u200C )は識別子中に記述できます(ただし、先頭の文字としては使えません)。前述したとおり、バイトオーダーマーク制御文字( \uFEFF )は空白スペースとして扱われます。
ハードウェアやソフトウェアの都合により、全てのコンピュータが全ての Unicode 文字を表示できたり入力できたりするわけではありません。このような環境を利用しているプログラマをサポートするために、JavaScript では、6文字の ASCII 文字の並びで、Unicode の文字コード(16ビット)を表現できるようにしています。この 6文字の ASCII 文字の並びを Unicode エスケープシーケンスと呼びます。Unicode エスケープシーケンスは、\u という文字から始め、その後に 4文字の 16進数( A~F、a~fを利用)を記述します。JavaScript の場合、Unicode エスケープシーケンスは、文字列リテラルや正規表現リテラル、識別子中に記述できます(ただし、JavaScript 言語のキーワードには記述できません)。例えば、「 é 」という文字の Unicode エスケープシーケンスは \u00E9 ですので、次の2つの文字列は JavaScriptでは同一と見なされます。
JavaScript
"café" === "caf\u00e9" // => trueコメント中にも Unicode エスケープシーケンスを記述できます。ただし、コメントは無視されますので、単に ASCII 文字として扱われているだけで、特に Unicode 文字として解釈されているわけではありません。
Unicode では、同じ文字を複数の方法で記述できます。例えば、「 é 」という文字は、Unicode 文字 \u00E9 として表記できます。また、通常の ASCII 文字「 e 」の後ろに鋭アクセント結合マーク( \u0301 )を続ける表記方法もあります。どちらの方法で文字を記述したとしても、画面上に表示されるときには全く同じ文字として見なされてしまいます。Unicode 標準では、全ての文字に対して、推奨する表記方法が定義されています。また、テキストを標準形式に変換するための手続きも規定されており、適切に比較できるようにしています。これに対して、JavaScript では、ソースコードはすでに正規化されていると想定しています。つまり、JavaScript 側では、識別子や文字列、正規表現の正規化処理は行いません。
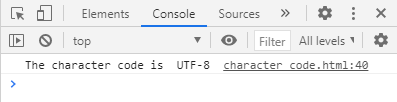
このページの文字コードを取得してみます。Webページの文字コード判別には、ドキュメント内の characterSet 属性を使用します。
JavaScript
const charaCode = document.characterSet;
console.log("The character code is ", charaCode);これを実行し、コンソール画面で確認すると「The character code is UTF-8」と表示されこのページの文字コードが UTF-8 であることがわかります。
これは HTMLドキュメント内の meta要素の charaset属性に UTF-8 を指定しているからです。
HTML
<!DOCTYPE html>
<html lang="ja">
<head>
<meta charset="utf-8">
<title>Character code</title>
<script>
const charaCode = document.characterSet;
console.log("The character code is ", charaCode);
</script>
</head>
<body>
...
</body>
</html>このセクションでは、数値から文字へ、文字から数値への変換を行う方法をご紹介したいと思います。これからご紹介するサンプルコードで使用する文字コードは「Unicode」です。
Unicode値である数値から文字への変換を行ってみます。
Stringオブジェクトの fromCharCodeメソッドを使用し、数値から文字に変換しました。fromCharCodeメソッドは引数に変換したい数値を指定するのみの、シンプルなメソッドです。
JavaScript
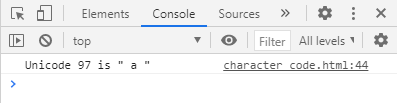
const ccNum = String.fromCharCode(97);
console.log('Unicode 97 is "', ccNum, '"');変数 ccNum に fromCharCodeメソッドの戻り値である文字を格納し、それを JavaScriptコンソールに表示させました。実際、97 は小文字の英字 a なので、コンソールに「Unicode 97 is " a "」と表示されました。
文字からUnicode値への変換を行ってみます。
charCodeAtメソッドを使用し、文字を数値に変換しました。charCodeAtメソッドの構文は「任意の文字列.charCodeAt(位置)」です。
JavaScript
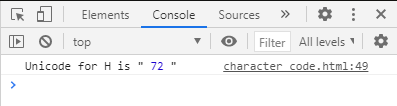
const str = "Hello";
const ccAt = str.charCodeAt(0);
console.log('Unicode for H is "', ccAt,'"');任意の文字列は Hello と指定し、数値に変換したい文字は一番目(配列の 0番目)の H と指定しました。H の Unicode値は 72 です。なので、コンソールには「Unicode for H is " 72 "」と表示されました。
外部ファイルを使用する際、JavaScriptコードが HTMLファイルとは違う文字コードを使用している場合、文字化けが起こったり正しく動作しないことがあります。
そんな時は、外部 JavaScriptファイルを呼び出す際に、文字コードを指定することで対処できます。
HTML
<script src="example.js" charset="UTF-8"></script>Unicodeはすべての文字(制御文字などの画面に表示されない文字も含む)に対して IDを定義する目的で策定されている仕様です。この「文字」に対する「一意の ID」のことを Code Point(符号位置)と呼びます。
Code Pointを扱うメソッドの多くは、ECMAScript 2015で追加されています。 ES2015で追加された String.codePointAtメソッドや String.fromCodePointメソッドを使うことで、文字列と Code Pointを相互変換できます。
String.codePointAtメソッドは、文字列の指定インデックスにある文字の Code Pointの値を返します。
JavaScript
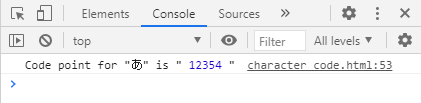
const cpAt = "あ".codePointAt(0);
console.log('Code point for "あ" is "', cpAt, '"');ここの例では、文字列「あ」の Code pointを取得してみました。結果は「12354」となります。
単純に結果の Code pointの値のみをコンソールに表示させるだけであれば、
JavaScript
console.log("あ".codePointAt(0));と、書き直すこともできます。
一方の String.fromCodePointメソッドは、指定した Code Pointに対応する文字を返します。
JavaScript
// Code Pointが`12354`の文字を取得する
console.log(String.fromCodePoint(12354));
// `12354`を16進数リテラルで表記しても同じ結果
console.log(String.fromCodePoint(0x3042));この2つの例はどちらも同じ結果となり文字列の「あ」を表示します。